이번 글에선 트랜스포머의 기반이 되는 어텐션 메커니즘에 대해서 정리해보고자 한다. 반드시 확실하게 알아두어야 할 개념이라 https://wikidocs.net/22893를 정독하고 나름대로 이해한 내용을 정리하였다.
1. 어텐션 메커니즘
보통 RNN을 사용하는 seq2seq 모델은 인코더와 디코더로써 각각의 RNN을 사용하여 구현된다. seq2seq 모델의 특징은 순차적으로 입력값을 입력받아 순차적으로 출력 값을 출력하는 형태이다. 아래 그림을 보자.

seq2seq모델의 인코더는 순차적으로 단어를 입력받아 RNN내부 계산을 통해 context 벡터를 생성한다. context 벡터는 인코더로 입력된 문장의 모든 단어들을 압축한 정보라고 볼 수 있다. 이 context 벡터는 디코더 RNN의 히든 state로 입력되어 <sos>토큰을 시작으로 출력 값을 순차적으로 예측하여 출력하게 된다.
이러한 seq2seq 모델은 문제점이 있다. 인코더의 입력 시퀀스가 매우 긴 경우를 생각해보자. 하나의 고정된 크기의 벡터에 모든 정보를 압축하여 context 벡터를 생성하게 되면 처음 입력되었던 단어에 대한 특징은 여러 번의 연산을 거치며 거의 남아있지 않게 될 것이다. 즉, 정보 손실이 발생하게 되는 것이다.
결국 이는 기계 번역 분야에서 입력 문장이 길어지면 번역 품질이 떨어지는 결과로 이어질 수밖에 없다.
이를 위한 대안으로 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위해 등장한 기법이 이번에 소개할 어텐션(attention)이다.
1.1 정보 손실을 막기 위한 방법
정보 손실을 막기 위한 어텐션의 아이디어는 디코더 RNN의 히든 스테이트 입력(context)을 생성할 때 인코더 RNN의 모든 히든 스테이트를 다시 참조하여 context 벡터를 생성하도록 하는 것이다. 이때 인코더 RNN의 모든 히든 스테이트를 동일한 비율로 참조하는 것이 아닌 집중(attention)하여야 할 단어에 가중치를 준다.
예를 들어 현시점에서 예측해야 할 단어와 연관이 있는 입력 단어의 히든 스테이트에 큰 가중치를 두고, 반대로 연관이 없는 입력 단어의 히든 스테이트에는 작은 가중치를 주어 참조하게 된다.
이렇게 어텐션 모델은 이전에 있었던 RNN 인코더의 기억을 다시 상기시킴으로써 정보 손실을 보정한다.
1.2 어텐션 함수
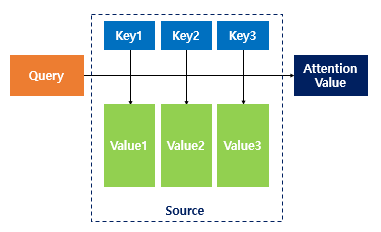
어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영해준다. 그리고 유사도가 반영된 '값(Value)'을 모두 더해서 리턴하게된다. 이때 구하는 유사도를 기반으로 어텐션 가중치를 구하게 되는데 이것이 앞서 설명한 현시점에서 어떤 단어에 집중할지를 결정하는 가중치가 된다.
어텐션 함수에 대해서 정리하자면
- '쿼리(Query)'와 '키(Key)'간의 유사도를 구하는 과정을 통해 어텐션 가중치를 구한다.
- 어텐션 가중치를 사용하여 벨류에대한 가중합을 구함으로써 문맥 정보를 포함하는 컨텍스트 벡터(context vector)를 구한다.
지금부터 설명하게 되는 seq2seq + 어텐션 모델에서 Q, K, V에 해당되는 각각의 Query, Keys, Values는 각각 다음과 같다.
- Q = Query : t 시점의 디코더 셀에서의 은닉 상태
- K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- V = Values : 모든 시점의 인코더 셀의 은닉 상태들
2. 닷-프로덕트 어텐션(Dot-Product Attention)
어텐션은 다양한 종류가 있는데 이번 글에서는 닷-프로덕트 어텐션에 대해 정리해보고자 한다. 트랜스포머에서는 닷-프로덕스 어텐션 스코어에서 key벡터 차원수의 제곱근에 해당하는 값을 나눠준 스케일드 닷 프로덕트 어텐션을 사용한다. 이는 이후 트랜스포머 정리에서 다뤄 보도록 하겠다.

위 그림은 디코더의 세번째 LSTM 셀에서 출력 단어를 예측할 때, 어텐션 메커니즘을 사용하는 모습을 보여준다. 디코더의 첫 번째, 두 번째 LSTM 셀은 이미 어텐션 메커니즘을 통해 je와 suis를 예측하는 과정을 거쳤다고 가정하고 어텐션 메커니즘이 어떻게 동작하는지 자세히 알아보도록 하자.
seq2seq에서 어텐션 메커니즘은 총 5단계로 이루어진다.
step1 어텐션 스코어(attention score)를 구한다.
어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현시점의 은닉 상태 \(s_t\)와 얼마나 유사한지를 판단하는 스코어값이다.
닷-프로덕트 어텐션에서는 이 스코어 값을 구하기 위해 \(s_t\)를 전치(transpose)하고 각 은닉 상태와 내적(dot product)을 수행한다. 예를 들어\(s_t\)와 인코더의 i번째 은닉 상태의 어텐션 스코어의 계산 방법은 아래와 같다.

어텐션 스코어 함수를 정의해보면 다음과 같다.

어텐션 스코어는 모든 인코더의 히든 스테이트에 대해서 구해지므로 아래와 같이 모든 히든스테이트에 대한 어텐션 스코어를 백터로 나타낼 수 있다.
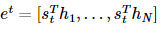
step2 소프트맥스(softmax) 함수를 통해 어텐션 분포(Attention Distribution)를 구한다.

위에서 구한 \(e^t\)에 소프트맥스 함수를 적용하여, 모든 값을 합하면 1이 되는 확률 분포를 얻을 수 있다. 이를 어텐션 분포(Attention Distribution)라고 하며, 각각의 값은 어텐션 가중치(Attention Weight)라고 한다.
디코더의 시점 t에서의 어텐션 가중치의 모음 값인 어텐션 분포를 \(\alpha^{t}\)이라고 할 때, \(\alpha^{t}\)을 식으로 정의하면 다음과 같다.
\[\alpha^{t} = softmax(e^{t})\]
step3 각 인코더의 어텐션 가중치와 은닉 상태를 가중합 하여 어텐션 값(Attention Value)을 구한다.

어텐션의 최종 결괏값을 얻기 위해서 각 인코더의 히든 스테이트와 어텐션 가중치값들을 곱하고, 최종적으로 모두 더하는 가중합(Weighted Sum)을 진행합니다. 어텐션 함수의 출력 값인 어텐션 값(Attention Value) \(a^t \)에 대한 식은 아래와 같다.
\[a^t = \sum_{i=1}^{N} \alpha _{i}^{t} h_{i}\]
이러한 어텐션 값 \(a^t \)는 문맥의 정보를 포함하고 있다고 하여 컨텍스트 벡터(context vector)라고도 부른다.
step4 어텐션 값과 디코더의 t 시점의 히든 스테이트를 연결한다.(Concatenate)

이후에 위 과정으로부터 얻은 어텐션 값을 현시점의 디코더 히든 스테이트에 연결한다. 이와 같이 인코더로부터 얻은 어텐션 값을 디코더 히든 스테이트에 활용함으로써 더욱 정확한 예측을 할 수 있도록 하는 것이 어텐션 메커니즘의 핵심이다.
step5 출력층 연산의 입력이 되는 \(\tilde {s}_{t}\)를 계산한다.

위 과정으로부터 얻은 \(v_t\)는 출력층에 활동될 수 있는 벡터 형태로 변환이 필요하다. 때문에 Dense leyer를 통해 벡터의 차원을 출력층에 맞도록 축소하고 tanh를 거쳐 출력층의 softmax함수를 사용할 수 있도록 하여 \(\tilde {s}_{t}\)를 생성한다. 이를 수식으로 표현하면 아래와 같다.
\[\tilde {s}_{t} = tanh(W_c[a_t;s_t]+b_c)\]
step6 \(\tilde{s}_{t}\)를 출력층의 입력으로 사용하여 예측 값을 얻는다.
\(\tilde{s}_{t}\)를 출력층의 입력으로 사용하여 예측 벡터를 얻는다. 수식으로 표현하면 아래와 같다.
\[\hat{y}_t = Softmax(W_y\tilde{s}_t + b_y)\]
마치며
지금까지 seq2seq에서 정보 손실 문제를 해결할 수 있는 어텐션 메커니즘에 대해 알아보았다.
어텐션 메커니즘은 어텐션 스코어를 구하는 과정에 따라 종류가 다양한데 이 글에서는 닷-프로덕트 어텐션을 정리해 보았다. 어텐션 메커니즘은 고안한 사람의 이름을 따기도 하는데 닷-프로덕트 어텐션을 루옹(Luong) 어텐션이라고도 한다.
이후에 루옹 어텐션 외에도 바다나우(Bahdanau) 어텐션에 대해서도 정리해 볼 생각이다.
어텐션의 여러 종류는 아래 표와 같다.

어텐션 메커니즘은 그 자체로 seq2seq를 대체하고 있는 추세이다. 대표적으로 트랜스포머(Transformer)가 그러하다. 트랜스포머에서는 Vaswani가 고안한 스케일드 닷-프로덕스(scaled dot) 어텐션을 사용하는데 트랜스포머에 대해 정리하면서 스케일드 닷-프로덕트에 대해서도 다루어 보도록 하겠다.
댓글