이전에 소개했던 부스팅(Boosting)에 이어서 XGBoost에 대해 정리해보려고 한다.
출처 : 이 글은고려대학교 강필성 교수님의 강의를 바탕으로 작성한 것입니다.
1. XGBoost
GBM 알고리즘의 종류 중 하나로서 보다 빠르게 해를 찾아가는 과정에서 병렬 처리를 가능하게 하고자 하는 목적으로 설계된 알고리즘이다. 또한 GBM의 단점인 느린 수행 시간과 과적합 규제(R)부재 등의 문제 개선하고자 고안된 모델이다. X는 extrem을 의미하는데 GBM의 성능을 극한까지 끌어올렸다 라는 의미로 XGBoost라고 불린다고 생각하면 될 것 같다. 이제 XGBoost의 핵심적인 아이디어에 대해 개념적으로 정리해보려고 한다.
- Split finding algorithm
- 의사결정 나무에서의 Basic exact greedy algorithm
- 장점 : 항상 최적의 분기(split)를 찾을 수 있다. 왜냐하면 모든 가능한 분기점(split point)을 완전 탐색하여 가장 좋은 것을 찾기 때문이다.
- 단점 : 데이터가 너무 크면 메모리 문제가 발생할 수 있고, 완전 탐색을 하기 때문에 병렬 처리가 불가능하다.
- 의사결정 나무에서의 Basic exact greedy algorithm
1.1 Approximate algorithm
- 각각의 변수들에 의해서 트레이닝 데이터를 정렬을 시켜놓고 백분위에 의해 분할
- 분할은 tree 단위에서, split단위에서 할 수 있다.
- l개의 버켓(bucket)들에 대해 분기점을 찾는다.
- 모든 버켓(bucket)들의 최적의 분기점(max 정보획득률)을 찾고 그중 가장 좋은 분기점을 전체의 분기점으로 정한다.
아래 예시를 통해 Approximate algorithm에 대해 이해해 보도록 하자.

먼저 데이터가 정렬되어 있다는 가정하에서 데이터를 버켓으로 나눈다.
각각의 버켓에 대해서 분기를 통해 gradiant를 계산하면서 최적의 분기점을 찾는다.
가운데에 있는 파란색이 칠해진 버켓에 대해서 중간 지점을 분기점으로 한다면 정보획득량이 최대일 것이다.
이러한 과정이 주는 이점은 무엇일까?
n개의 데이터가 있을 때, n = 40이라고 가정해보자.
먼저 의사결정 나무에서 exact greedy 방식으로 위의 그림에서 최적의 분기점을 찾는다면 데이터의 개수가 n개 일 때 n-1번의 정보획득량을 조사해야 한다. 즉 39회의 연산이 필요하다.
반면 Approximate 방식은 분할된 버켓의 데이터수가 m개 일 때 m - 1번의 정보획득량을 조사한다. 40개의 데이터를 10개의 버켓으로 분할했다고 하면 m = 4가 된다. 따라서 3번의 정보획득량을 조사한다. 버켓이 총 10개이기 때문에 총 30회의 연산이 필요하게 된다. 이때 각각의 버킷은 병렬 처리가 가능하다. 정리하자면
- exact greedy : 39회
- approximate : 3 * 10회(병렬 처리 가능)
이처럼 버켓으로 나누어 병렬 처리함으로써 더욱 빠르게 분기 지점을 찾을 수 있다. 하지만 greedy 알고리즘에서 찾을 수 있는 최적의 분기점이 찾아지지 않을 가능성이 있다.
1.2 Global variant VS Local variant
아래는 Tree단위에서의 split (Global variant)의 예시이다.

위 그림에서 알 수 있듯 트리의 깊이가 깊어질수록 탐색해야 하는 버킷의 개수가 줄어든다. 또한 버켓 내부의 데이터 수는 분기점을 제외하고 동일하게 유지된다.
아래 예시는 split단위에서의(Local variant) 예시이다.

Local variant는 각각의 자식 노드들에 대해서 버켓 사이즈를 유지한다. 왼쪽 오른쪽 노드 각각 10개의 버켓을 가지게 된다. Local variant는 스플릿이 되더라도 버켓 사이즈가 유지가 되기 때문에 깊이가 깊어질수록 하나의 버켓에 들어가는 데이터는 단조 감소한다.
이러한 방법을 이용하여 split의 후보 수도 줄임과 동시에 병렬화도 가능하다.

XGBoost에서는 트리 분기에 있어 ϵ이라는 하이퍼 파라미터를 사용한다. ϵ 은 버켓을 나누는 기준이 되는데 1/ϵ 만큼의 버켓이 생긴다고 이해하면 된다. 만약 ϵ 이 0.3이라면 버켓이 3개 0.05라면 대략 20개의 버켓이 생성된다.
위 그래프에서 알 수 있듯 local variant는 global variant보다 ϵ 을 크게 잡아도 exact greedy 알고리즘과 비슷한 성능을 내지만 global variant를 사용할 때는 ϵ 을 보다 작게 설정해야 함을 알 수 있다.
1.3 Sparsity-Aware Split Finding
실제 데이터 같은 경우는 missing 데이터가 많이 발생한다. XGboost에서는 학습 과정에서 각각의 split 마다 default 디렉션을 찾아내어 이러한 missing 데이터를 처리할 수 있다. 아래 그림을 보자.

데이터가 정렬되어 있다고 가정할 때, missing 데이터를 전부 왼쪽으로 보내거나 전부 오른쪽으로 보내 정보 획득률을 조사하여 정보획득이 컸을 때를 기준으로 default direction은 찾아낸다. 위의 예시의 경우 default direction은 왼쪽으로 보냈을 때의 정보 획득률이 더 높으므로 왼쪽 자식 노드가 된다.
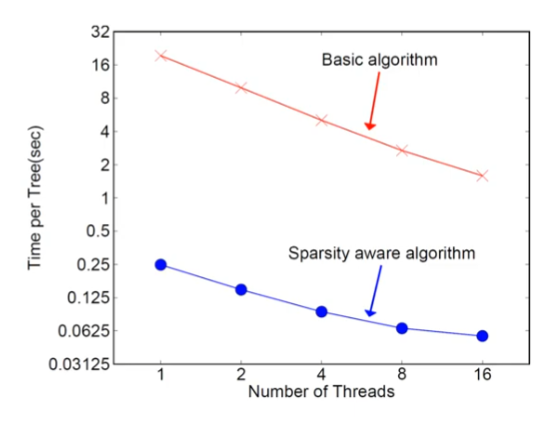
위와 같이 Sparsity aware를 사용하였을 때 트리 학습이나 예측에서의 계산시간을 상당히 줄일 수 있음을 알 수 있다.
'머신러닝, 딥러닝 > Ensemble' 카테고리의 다른 글
| Light GBM (0) | 2022.01.09 |
|---|---|
| Boosting (0) | 2022.01.08 |
| [ML] 랜덤 포레스트(Random Forest) (0) | 2022.01.08 |



댓글