-목차-
iris 데이터 K-means 테스트 코드 : iris_K-means_test
1. K-평균(K-Means) 알고리즘이란?
K-평균은 군집화(Clustering)에서 가장 일반적으로 사용되는 알고리즘이다. K-평균은 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다.
군집 중심점은 선택된 포인트의 평균 지점으로 이동하고 이동된 중심점에서 다시 가까운 포인트를 선택, 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행한다. 모든 데이터 포인트에서 더 이상 중심점의 이동이 없을 경우에 반복을 멈추고 해당 중심점에 속하는 데이터 포인트들을 군집화 하는 기법이다. 아래 그림은 K-평균이 어떻게 동작하는지를 시각적으로 표현한 것이다.

K-means의 알고리즘은 다음과 같이 동작한다.
- 클러스터의 개수인 K 결정
- 초기 K개의 중심점(centroid) 선정
- 일반적으로 k-means++ 방식으로 최초 설정
- 모든 데이터 포인트를 순회하며 가장 가까운 중심점이 있는 클러스터로 할당
- 중심점을 할당된 데이터 포인트의 중심점으로 이동
- 중심점의 이동이 없을 때까지 3, 4번 과정 반복
k-평균 알고리즘은 벡터 형태로 표현된 \(N\) 개의 데이터 \(X = \left\{ x_1, x_2, ..., x_N\right\}\)에 대하여 데이터가 속한 cluster의 중심과 데이터간의 거리의 차이가 최소가 되도록 데이터들을 \(K\)개의 cluster \(S = \left\{ s_1, s_2, ..., s_K\right\}\)에 할당한다. 많은 연구에서 \(K\)를 자동으로 설정하기 위한 시도가 이루어졌지만, 기본적으로 \(K\)는 데이터를 분석하고자 하는 사람이 직접 설정해주어야 한다. 어떠한 방법을 통해 \(K\)를 설정하였다고 가정할 때, k-평균 알고리즘은 아래의 최적화 문제로 표현될 수 있다.
\[\underset{r, c}{argmin} = \sum_{n=1}^{N}\sum_{k=1}^{K}r_{nk}\left\| x_n-c_k\right\|^2\]
이때 \(r_{nk}\)는 \(n\)번째 데이터가 \(k\)번째 cluster에 속하면 1, 아니면 0을 가지는 binary variable이며 \(c_{k}\)는 \(k\)번째 cluster의 중심점(centroid)을 뜻한다.
2. 군집 평가(Cluster Evaluation)
2.1 실루엣 분석(Silhouette analysis)
clusering 평가 방법으로 실루엣 분석(Silhouette analysis)이 있다. 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다.
효율적으로 잘 분리됐다는 것은 cluster 간의 거리는 떨어져 있고 동일 cluster내부 데이터는 서로 가깝게 잘 뭉쳐 있는 것을 의미한다.
실루엣 분석은 실루엣 계수(silhouette coefficient)를 기반으로 이루어 지는데, 실루엣 계수는 개별 데이터가 가지는 clustering 지표이다. 개별 데이터가 가지는 실루엣 계수는 해당 데이터가 같은 cluster 내의 데이터와 얼마나 가깝게 군집화 되어 있고, 다른 cluster에 있는 데이터와는 얼마나 멀리 분리돼 있는지를 나타내는 지표이다.
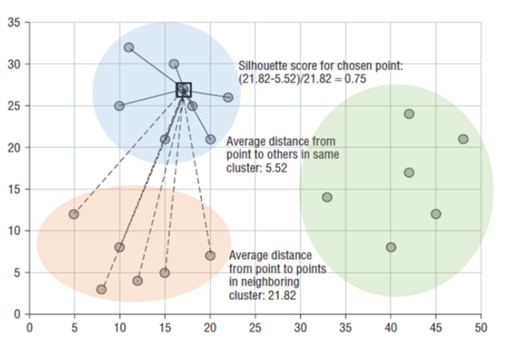
특정 데이터 포인트의 실루엣 계수 값은 해당 데이터 포인트와 같은 cluster내에 있는 다른 데이터 포인트와의 거리를 평균한 값을 \(a(i)\), 해당 데이터 포인트가 속하지 않은 cluster 중 가장 가까운 cluster와의 평균 거리를 \(b(i)\)라고 할 때, \(a(i)\), \(b(i)\)두 값을 기반으로 계산된다.
두 cluster간의 거리가 얼마나 떨어져 있는가의 값은 \(b(i) - a(i)\)이며 이 값을 정규화하기 위해 \(MAX(a(i), b(i))\) 값으로 나눈다. 따라서 \(i\) 번째 데이터 포인트의 실루엣 계수 값 \(s(i)\)는 다음과 같이 정의된다.
\[s(i) = \frac{b(i)-a(i)}{max(a(i), b(i))}\]
실루엣 계수는 -1에서 1사이의 값을 가지며, 1로 가까워질수록 근처의 cluster와 더 멀리 떨어져 있다는 것이고 0에 가까울수록 근처의 cluster와 가까워진다는 것이다. -값은 아예 다른 cluster에 데이터 포인트가 할당됐음을 의미한다.
참고 자료
'머신러닝, 딥러닝 > Clustering' 카테고리의 다른 글
| [ML] DBSCAN(Density Based Spatial Clustering of Applications with Noise) (0) | 2022.03.02 |
|---|---|
| [ML] GMM(Gaussian Mixture Model) (0) | 2022.03.02 |
| [ML] 평균 이동(Mean Shift) 군집화 (0) | 2022.03.02 |



댓글