-목차-
DBSCAN 테스팅 코드 : DBSCAN_test(K-means, GMM 비교)
1. DBSCAN의 개요
DBSCAN은 간단하고 직관적인 알고리즘으로 돼있음에도 데이터 분포가 기하학적으로 복잡한 데이터에도 효과적인 clustering이 가능하다. 아래와 같이 내부의 원 모양과 외부의 원 모양 형태의 분포를 가진 데이터를 clustering 한다고 가정할 때 K-means, Means-Shift, GMM으로는 효과적인 군집화를 수행하기가 어렵다. DBSCAN은 특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고 있어 복잡한 기하학적 분포도를 가진 데이터에 대해서도 clustering을 잘 수행한다.

2. DBSCAN의 작동원리
먼저 DBSCAN을 구성하는 가장 중요한 두가지 파라미터는 입실론(epsilon)으로 표기하는 주변 영역과 이 입실론 주변 영역에 포함되는 최소 데이터의 개수 min points이다.
- 입실론 주변 영역(epsilon) : 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 최소 데이터 개수(min points) : 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
입실론 주변 영역 내에 포함되는 최소 데이터 개수를 충족시키는가 아닌가에 따라 데이터 포인트를 다음과 같이 정의한다.
- 핵심 포인트(Core Point) : 주변 영역 내에 최소 데이터 개수 이상의 타 데이터를 가지고 있을 경우 해당 데이터를 핵심 포인트라고 한다.
- 이웃 포인트(Neighbor Point) : 주변 영역 내에 위치한 타 데이터를 이웃 포인트라고 한다.
- 경계 포인트(Border Point) : 주변 영역 내에 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않지만 핵심 포인트를 이웃 포인트로 가지고 있는 데이터를 경계 포인트라고 한다.
- 잡음 포인트(Nosie Point) : 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않으며, 핵심 포인트도 이웃 포인트로 가지고 있지 않는 데이터를 잡음 포인트라고 한다.
이해를 돕기 위해 아래 그림을 보자 그림 출처 : https://bcho.tistory.com/1205
아래 그림에서 min points = 4 라고 가정하자. 파란점 P를 중심으로 반경 epsilon 내에 5개의 데이터가 있으므로 P는 core point가 된다.

다음으로 P2의 경우 점 P2를 중심으로 epsilon 반경내의 데이터가 3개 이기 때문에, min points = 4 에 미치지 못하므로 core point는 되지 못하지만, 이웃 데이터 중에 앞서 core point인 P를 가지고 있으므로 boder point (경계점)가 된다. 경계 포인트는 cluster의 외곽을 형성한다.

아래 그림에서 P3는 epsilon 반경내에 점 4개를 가지고 있기 때문에 핵심 포인트(core point)가 된다. 핵심 포인트는 직접 접근이 가능한 다른 핵심 포인트를 서로 연결하면서 cluster를 구성한다. 이러한 방식으로 점차적으로 cluster 영역을 확장해 나가는 것이 DBSCAN이다.

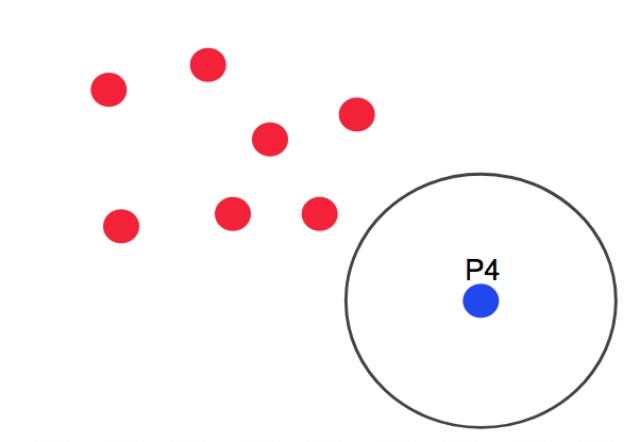
마지막으로 아래 그림의 P4 반경 내에 최소 데이터를 가지고 있지도 않고, 핵심 포인트 또한 이웃 데이터로 가지고 있지 않는 데이터를 잡음 포인트(Noise Point)라고 한다.
이를 모두 정리해보면 아래와 같은 결과가 된다.

DBSCAN은 이처럼 입실론 주변 영역의 최소 데이터 개수를 포함하는 밀도 기준을 충족시키는 데이터인 핵심 포인트를 연결하면서 군집화를 수행하는 방식이라고 할 수 있다.
DBSCAN의 장점
- K-Means와 같이 cluster의 수를 정하지 않아도 된다.
- cluster의 밀도에 따라서 cluster를 서로 연결하기 때문에 기하학적인 모양을 갖는 cluster도 clustering이 잘 이루어진다.
- Noise Point를 통하여 이상치(Outlier) 검출이 가능하다.
참고 자료
'머신러닝, 딥러닝 > Clustering' 카테고리의 다른 글
| [ML] GMM(Gaussian Mixture Model) (0) | 2022.03.02 |
|---|---|
| [ML] 평균 이동(Mean Shift) 군집화 (0) | 2022.03.02 |
| [ML] K-평균(K-means) 알고리즘 (0) | 2022.03.01 |



댓글